Recently I completed a small project, including an embedded microcontroller. For me, using the popular Arduino IDE, and C, was a mistake. The experience with Rust was better, but still very exciting, and not in a good way.
Here follows the rant.
Introduction
In a recent project (I ll write about the purpose, and the hardware in another post) I chose to use a
DigiSpark board. This is a small board with a USB-A tongue (but not a proper plug), and an
ATTiny85 microcontroller, This chip has 8 pins and is quite small really, but it was plenty for my application. By choosing something popular, I hoped for convenient hardware, and an uncomplicated experience.
Convenient hardware, I got.
Arduino IDE
The usual way to program these boards is via an IDE. I thought I d go with the flow and try that. I knew these were closely related to actual Arduinos and saw that the IDE package
arduino was in Debian.
But it turns out that the Debian package s version doesn t support the DigiSpark. (AFAICT from the list it offered me, I m not sure it supports
any ATTiny85 board.) Also, disturbingly, its board manager seemed to be offering to install board support, suggesting it would download stuff from the internet and run it. That wouldn t be acceptable for my main laptop.
I didn t expect to be doing much programming or debugging, and the project didn t have significant security requirements: the chip, in my circuit, has only a very narrow ability do anything to the real world, and no network connection of any kind. So I thought it would be tolerable to do the project on my low-security video laptop . That s the machine where I m prepared to say yes to installing random software off the internet.
So I went to the
upstream Arduino site and downloaded a tarball containing the Arduino IDE. After unpacking that in
/opt it ran and produced a pointy-clicky IDE, as expected. I had already found
a 3rd-party tutorial saying I needed to add a magic URL (from the DigiSpark s vendor) in the preferences. That indeed allowed it to download a whole pile of stuff. Compilers, bootloader clients, god knows what.
However, my tiny test program didn t make it to the board. Half-buried in a too-small window was an error message about the board s bootloader ( Micronucleus ) being too new.
The boards I had came pre-flashed with micronucleus 2.2. Which is hardly new, But even so the official Arduino IDE (or maybe the DigiSpark s board package?) still contains an old version. So now we have all the downsides of
curl bash-ware, but we re lacking the it s up to date and it just works upsides.
Further digging found some
random forum posts which suggested simply downloading
a newer micronucleus and manually stuffing it into the right place: one overwrites a specific file, in the middle the heaps of stuff that the Arduino IDE s board support downloader squirrels away in your home directory. (In my case, the home directory of the untrusted shared user on the video laptop,)
So, whatever . I did that. And it worked!
Having demo d my ability to run code on the board, I set about writing my program.
Writing C again
The programming language offered via the Arduino IDE is C.
It s been a little while since I started a new thing in C. After having spent so much of the last several years writing Rust. C s primitiveness quickly started to grate, and the program couldn t easily be as DRY as I wanted (Don t Repeat Yourself, see
Wilson et al, 2012, 4, p.6). But, I carried on; after all, this was going to be quite a small job.
Soon enough I had a program that looked right and compiled.
Before testing it in circuit, I wanted to do some QA. So I wrote a simulator harness that
#included my Arduino source file, and provided imitations of the few Arduino library calls my program used. As an side advantage, I could build and run the simulation on my main machine, in my normal development environment (Emacs,
make, etc.). The simulator runs confirmed the correct behaviour. (Perhaps there would have been some more faithful simulation tool, but the Arduino IDE didn t seem to offer it, and I wasn t inclined to go further down that kind of path.)
So I got the video laptop out, and used the Arduino IDE to flash the program. It didn t run properly. It hung almost immediately. Some very ad-hoc debugging via led-blinking (like printf debugging, only much worse) convinced me that my problem was as follows:
Arduino C has 16-bit ints. My test harness was on my 64-bit Linux machine. C was autoconverting things (when building for the micrcocontroller). The way the Arduino IDE ran the compiler didn t pass the warning options necessary to spot narrowing implicit conversions. Those warnings aren t the default in C in general
because C compilers hate us all for compatibility reasons.
I don t know why those warnings are not the default in the Arduino IDE, but my guess is that they didn t want to bother poor novice programmers with messages from the compiler explaining how their program is quite possibly wrong. After all, users don t like error messages so we shouldn t report errors. And novice programmers are especially fazed by error messages so it s better to just let them struggle themselves with the arcane mysteries of undefined behaviour in C?
The Arduino IDE does offer a dropdown for compiler warnings . The default is None. Setting it to All didn t produce anything about my integer overflow bugs. And, the output was very hard to find anyway because the log window has a constant stream of strange messages from
javax.jmdns, with hex DNS packet dumps. WTF.
Other things that were vexing about the Arduino IDE: it has fairly fixed notions (which don t seem to be documented) about how your files and directories ought to be laid out, and magical machinery for finding things you put nearby its sketch (as it calls them) and sticking them in its ear, causing lossage. It has a tendency to become confused if you edit files under its feet (e.g. with
git checkout). It wasn t really very suited to a workflow where principal development occurs elsewhere.
And, important settings such as the project s clock speed, or even the target board, or
the compiler warning settings to use weren t stored in the project directory along with the actual code. I didn t look too hard, but I presume they must be in a dotfile somewhere. This is madness.
Apparently there is an Arduino CLI too. But I was already quite exasperated, and I didn t like the idea of going so far off the beaten path, when the whole point of using all this was to stay with popular tooling and share fate with others. (How do these others cope? I have no idea.)
As for the integer overflow bug:
I didn t seriously consider trying to figure out how to control in detail the C compiler options passed by the Arduino IDE. (Perhaps this is
possible, but not really documented?) I did consider trying to run a cross-compiler myself from the command line, with appropriate warning options, but that would have involved providing (or stubbing, again) the Arduino/DigiSpark libraries (and bugs could easily lurk at that interface).
Instead, I thought, if only I had written the thing in Rust . But that wasn t possible, was it? Does Rust even support this board?
Rust on the DigiSpark
I did a cursory web search and found a very useful
blog post by Dylan Garrett.
This encouraged me to think it might be a workable strategy. I looked at the instructions there. It seemed like I could run them via the
privsep arrangement I use to protect myself when developing using upstream cargo packages from
crates.io.
I got surprisingly far surprisingly quickly. It did, rather startlingly, cause my
rustup to download a random recent Nightly Rust, but I have six of those already for other Reasons. Very quickly I got the trinket LED blink example, referenced by Dylan s blog post, to compile. Manually copying the file to the video laptop allowed me to run the previously-downloaded micronucleus executable and successfully run the blink example on my board!
I thought a more principled approach to the bootloader client might allow a more convenient workflow. I found the
upstream Micronucleus git releases and tags, and had a look over its source code, release dates, etc. It seemed plausible, so I compiled v2.6 from source. That was a success: now I could build and install a Rust program onto my board, from the command line, on my main machine. No more pratting about with the video laptop.
I had got further, more quickly, with Rust, than with the Arduino IDE, and the outcome and workflow was superior.
So, basking in my success, I copied the directory containing the example into my own project, renamed it, and adjusted the
path references.
That didn t work. Now it didn t build. Even after I copied about
.cargo/config.toml and
rust-toolchain.toml it didn t build, producing a variety of exciting messages, depending what precisely I tried. I don t have detailed logs of my flailing: the instructions say to build it by
cd ing to the subdirectory, and, given that what I was trying to do was to
not follow those instructions, it didn t seem sensible to try to prepare a proper repro so I could file a ticket. I wasn t optimistic about investigating it more deeply myself: I have some experience of fighting cargo, and it s not usually fun. Looking at some of the build control files, things seemed quite complicated.
Additionally, not all of the crates are on
crates.io. I have no idea why not. So, I would need to supply local copies of them anyway. I decided to just
git subtree add the
avr-hal git tree.
(That seemed better than the approach taken by the avr-hal project s
cargo template, since that template involve a cargo dependency on a foreign
git repository. Perhaps it would be possible to turn them into
path dependencies, but given that I had evidence of file-location-sensitive behaviour, which I didn t feel like I wanted to spend time investigating, using that seems like it would possibly have invited more trouble. Also, I don t like package templates very much. They re a form of clone-and-hack: you end up stuck with whatever bugs or oddities exist in the version of the template which was current when you started.)
Since I couldn t get things to build outside
avr-hal, I edited the example, within
avr-hal, to refer to my (one)
program.rs file
outside avr-hal, with a
#[path] instruction. That s not pretty, but it worked.
I also had to write a
nasty shell script to work around the lack of good support in my
nailing-cargo privsep tool for builds where
cargo must be invoked in a deep subdirectory, and/or
Cargo.lock isn t where it expects, and/or the
target directory containing build products is in a weird place. It also has to filter the output from
cargo to adjust the pathnames in the error messages. Otherwise, running both
cd A; cargo build and
cd B; cargo build from a
Makefile produces confusing sets of error messages, some of which contain filenames relative to
A and some relative to
B, making it impossible for my Emacs to reliably find the right file.
RIIR (Rewrite It In Rust)
Having got my build tooling sorted out I could go back to my actual program.
I translated the main program, and the simulator, from C to Rust, more or less line-by-line. I made the Rust version of the simulator produce the same output format as the C one. That let me check that the two programs had the same (simulated) behaviour. Which they did (after fixing a few glitches in the simulator log formatting).
Emboldened, I flashed the Rust version of my program to the DigiSpark. It worked right away!
RIIR had caused the bug to vanish. Of course, to rewrite the program in Rust, and get it to compile, it was necessary to be careful about the types of all the various integers, so that s not so surprising. Indeed, it was the point. I was then able to refactor the program to be a bit more natural and DRY, and improve some internal interfaces. Rust s greater power, compared to C, made those cleanups easier, so making them worthwhile.
However, when doing real-world testing I found a weird problem: my timings were off. Measured, the real program was too fast by a factor of slightly more than 2. A bit of searching (and searching my memory) revealed the cause: I was using a board template for an Adafruit Trinket. The Trinket has a clock speed of 8MHz. But the DigiSpark runs at 16.5MHz. (This is discussed in a
ticket against one of the C/C++ libraries supporting the ATTiny85 chip.)
The Arduino IDE had offered me a choice of clock speeds. I have no idea how that dropdown menu took effect; I suspect it was adding prelude code to adjust the clock prescaler. But my attempts to mess with the CPU clock prescaler register by hand at the start of my Rust program didn t bear fruit.
So instead, I adopted a bodge: since my code has (for code structure reasons, amongst others) only one place where it dealt with the underlying hardware s notion of time, I simply changed my
delay function to
adjust the passed-in delay values, compensating for the wrong clock speed.
There was probably a more principled way. For example I could have (re)based my work on either of the two
unmerged open MRs which added proper support for the DigiSpark board, rather than abusing the Adafruit Trinket definition. But, having a nearly-working setup, and an explanation for the behaviour, I preferred the narrower fix to reopening any cans of worms.
An offer of help
As will be obvious from this posting, I m not an expert in dev tools for embedded systems. Far from it. This area seems like quite a deep swamp, and I m probably not the person to help drain it. (Frankly, much of the improvement work ought to be done, and paid for, by hardware vendors.)
But, as a full Member of the Debian Project, I have considerable gatekeeping authority there. I also have much experience of software packaging, build systems, and release management. If anyone wants to try to improve the situation with embedded tooling in Debian, and is willing to do the actual packaging work. I would be happy to advise, and to review and sponsor your contributions.
An obvious candidate: it seems to me that
micronucleus could easily be in Debian. Possibly a DigiSpark board definition could be provided to go with the
arduino package.
Unfortunately, IMO Debian s Rust packaging tooling and workflows are very poor, and the first of my
suggestions for improvement wasn t well received. So if you need help with improving Rust packages in Debian, please talk to the
Debian Rust Team yourself.
Conclusions
Embedded programming is still rather a mess and probably always will be.
Embedded build systems can be bizarre. Documentation is scant. You re often expected to download board support packages full of mystery binaries, from the board vendor (or others).
Dev tooling is maddening, especially if aimed at novice programmers. You want version control? Hermetic tracking of your project s build and install configuration? Actually to be told by the compiler when you write obvious bugs? You re way off the beaten track.
As ever, Free Software is under-resourced and the maintainers are often busy, or (reasonably) have other things to do with their lives.
All is not lost
Rust can be a significantly better bet than C for embedded software:
The Rust compiler will catch a good proportion of programming errors, and an experienced Rust programmer can arrange (by suitable internal architecture) to catch nearly all of them. When writing for a chip in the middle of some circuit, where debugging involves staring an LED or a multimeter, that s precisely what you want.
Rust embedded dev tooling was, in this case, considerably better. Still quite chaotic and strange, and less mature, perhaps. But: significantly fewer mystery downloads, and significantly less crazy deviations from the language s normal build system. Overall, less bad software supply chain integrity.
The ATTiny85 chip, and the DigiSpark board, served my hardware needs very well. (More about the hardware aspects of this project in a future posting.)

comments

 Over roughly the last year and a half I have been participating as a reviewer in
ACM s
Over roughly the last year and a half I have been participating as a reviewer in
ACM s  It was pointed out to me that I have not blogged about this, so better now than never:
Since 2021 I am together with four other hosts producing a regular podcast about Haskell, the
It was pointed out to me that I have not blogged about this, so better now than never:
Since 2021 I am together with four other hosts producing a regular podcast about Haskell, the  This is a post I wrote in June 2022, but did not publish back then.
After first publishing it in December 2023, a perfectionist insecure
part of me unpublished it again. After receiving positive feedback, i
slightly amended and republish it now.
In this post, I talk about unpaid work in F/LOSS, taking on the example
of hackathons, and why, in my opinion, the expectation of volunteer work
is hurting diversity.
Disclaimer: I don t have all the answers, only some ideas and questions.
This is a post I wrote in June 2022, but did not publish back then.
After first publishing it in December 2023, a perfectionist insecure
part of me unpublished it again. After receiving positive feedback, i
slightly amended and republish it now.
In this post, I talk about unpaid work in F/LOSS, taking on the example
of hackathons, and why, in my opinion, the expectation of volunteer work
is hurting diversity.
Disclaimer: I don t have all the answers, only some ideas and questions.
 Earlier this year, after Github
Earlier this year, after Github  Now, I think it's safe to assume this program is dead and buried, and
anyways I'm running
Now, I think it's safe to assume this program is dead and buried, and
anyways I'm running  For multi-monitor setups,
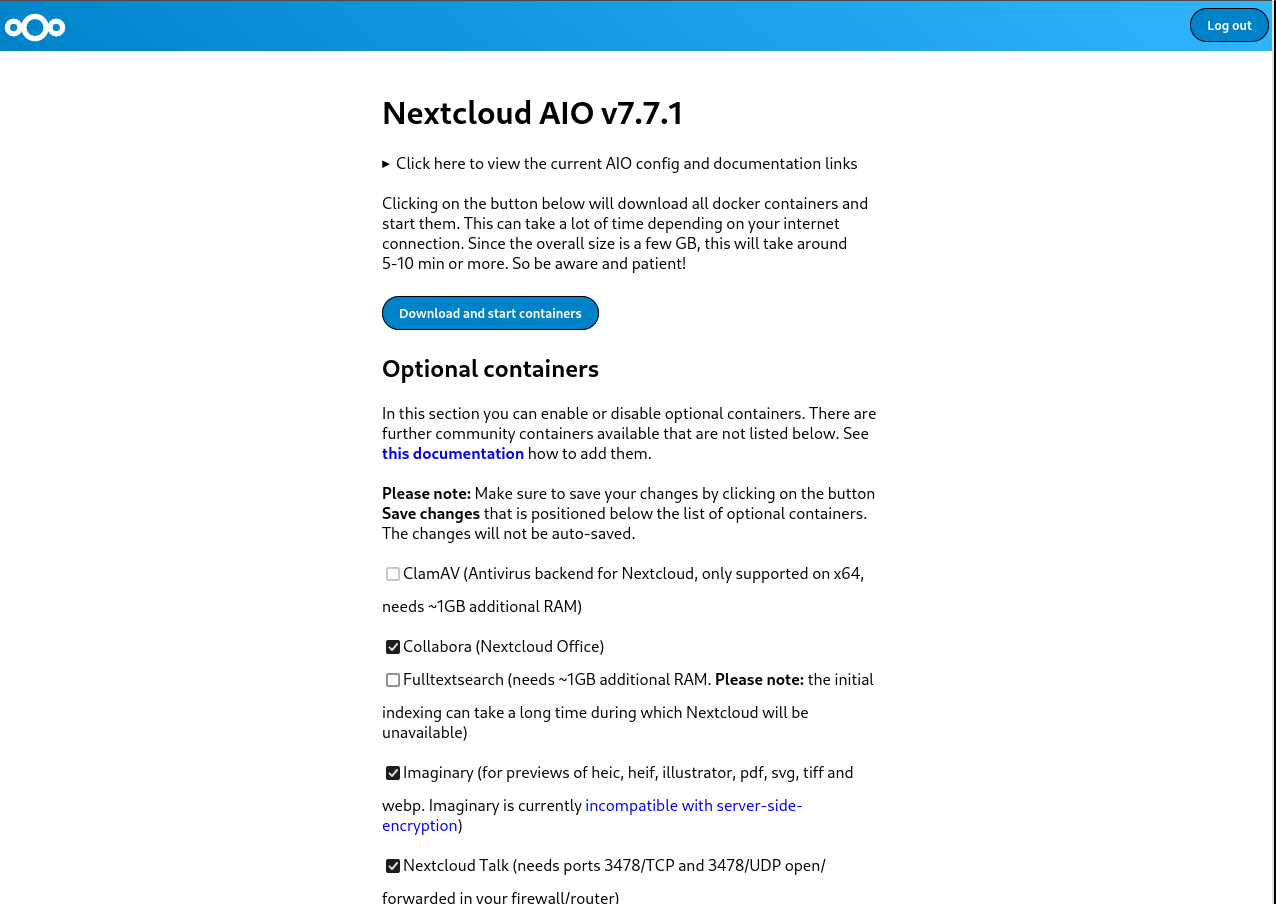
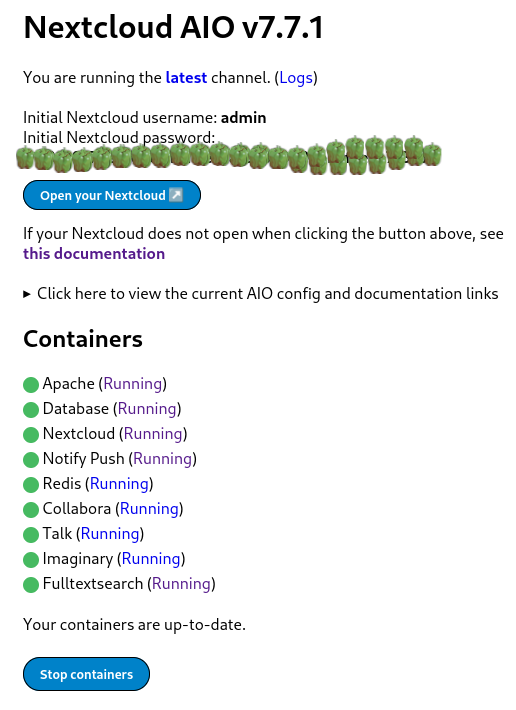
For multi-monitor setups,  Nextcloud is a popular self-hosted solution for file sync and share as well as cloud apps such as document editing, chat and talk, calendar, photo gallery etc. This guide will walk you through setting up Nextcloud AIO using Docker Compose. This blog post would not be possible without immense help from Sahil Dhiman a.k.a.
Nextcloud is a popular self-hosted solution for file sync and share as well as cloud apps such as document editing, chat and talk, calendar, photo gallery etc. This guide will walk you through setting up Nextcloud AIO using Docker Compose. This blog post would not be possible without immense help from Sahil Dhiman a.k.a. 













 Hello from a snowy Montr al! My life has been pretty busy lately
Hello from a snowy Montr al! My life has been pretty busy lately


















 My stall. Photo credits: Tejaswini.
My stall. Photo credits: Tejaswini.
 Snacks and tea at the front desk. CC-BY-SA 4.0 by Ravi Dwivedi.
Snacks and tea at the front desk. CC-BY-SA 4.0 by Ravi Dwivedi.
 Pictionary drawing nowhere close to the intended word Wireguard :), which was guessed. Photo by Ravi Dwivedi, CC-BY-SA 4.0.
Pictionary drawing nowhere close to the intended word Wireguard :), which was guessed. Photo by Ravi Dwivedi, CC-BY-SA 4.0.
 Group photo. Photo credits: Tejaswini.
Group photo. Photo credits: Tejaswini.
 Tasty cake. CC-BY-SA 4.0 by Ravi Dwivedi.
Tasty cake. CC-BY-SA 4.0 by Ravi Dwivedi.
 Merchandise by sflc.in. CC-BY-SA 4.0 by Ravi Dwivedi.
Merchandise by sflc.in. CC-BY-SA 4.0 by Ravi Dwivedi.